micahlerner.com
Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer
Published January 03, 2025
Found something wrong? Submit a pull request!
Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer
What is the research and why does it matter?
This paper shares Google’s techniques for operating a large cluster of machine learning resources (specifically, tensor processing units, aka “TPUs”) reliably and at scale.
A challenge the research discusses stems from the requirements of modern AI, which need significant computing power to train and serve models - in systems this large, component breakage leads to costly downtime in training and serving, a topic I previously touched on in Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints. The key insight from the paper is that dynamic network reconfiguration (e.g. to route network traffic from training models around faulty TPUs and to working ones) dramatically improves availability and scalability of the system.
How does the system work?
There are five main technical components of the system:
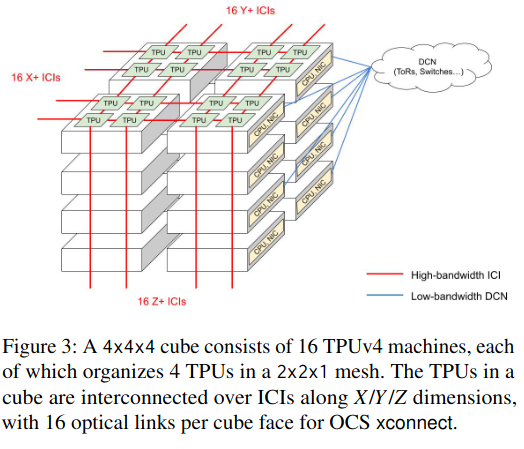
- TPU chips and their groupings into cubes (a “cube is a hardware unit with 64 TPU chips arranged in a 4x4x4 3D mesh”) and pods (64 cubes).
- The inter-chip interconnect (ICI), that directly interconnects TPUs to allow device-to-device communication (the paper cites Remote Direct Memory Access, aka RDMA) without involving the CPUs. The ICI is like the “highway” that connects network traffic.
- Optical circuit switches (OCSes) which contain mirrors that actually point the network traffic (in the form of light) on the right “highway” (provided by the ICI). This technology is discussed in more detail in Jupiter evolving: Transforming Google’s datacenter network via optical circuit switches and software-defined networking.
- The Borg cluster manager (described in previous research) combined with a Pod Manager to handle TPU-specific considerations (e.g. ensuring Pod connectivity and health).
- Code that allows TPUs to connect to one another (
liptpunet) and evaluates hardware health (healthd).
The key insight of the paper is that through the combination of existing general technologies (e.g. the Borg cluster scheduler) and TPU-specific adaptations (e.g. dynamically reconfiguring the network if a TPU pod has problems), it is possible to make a more resilient system that recovers from hardware failure/degradation quickly.
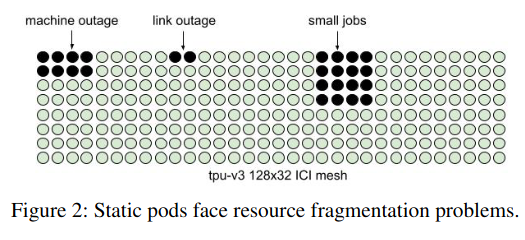
The design of the system is influenced by previous versions where connections between TPUs were static (in contrast with the new system where connections can be easily reconfigured) - “in a static pod, all resources in a contiguous set of nodes must be simultaneously healthy to be assigned to a user, which becomes combinatorially less likely as the system scales”.
Furthermore, static configurations posed three other challenges:
- Maintenance: updating any part of the stack that connects TPUs mandated downtime.
- Workload defragmentation: a job had to be scheduled across contiguous GPUs, which made it hard to schedule jobs at different priorities (e.g. training jobs vs smaller experiments). With dynamic network reconfiguration, jobs can shift resources and the connections to use them on demand.
- Deployment lead time: a TPU pod wasn’t available until all of the underlying resources were ready and installed. Now, TPU pods are usable even when only partially deployed.
How does reconfigurability work?
A key part of reconfigurability is quickly changing connectivity between TPU cubes/pods in response to failure or degradation. Two components work in concert to provide connectivity - the inter-chip interconnect (ICI) connects TPUs within a machine (4 TPU chips) and cube (16 machines), while the Optical circuit switches (OCSes) connect cubes (each containing 96 TPUs).
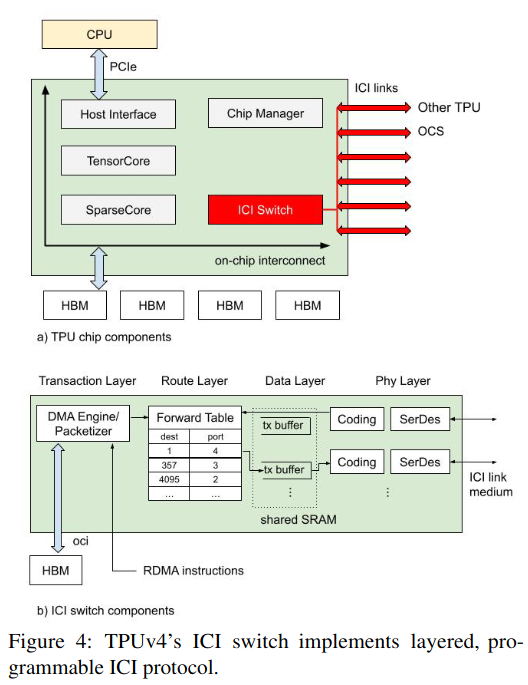
The ICI handles multiple levels of the networking stack, with technologies like RDMA (which supports collectives like “combine all of the data from other TPUs into a single result”) at the top-level.
The libtpunet software is responsible for setting up the inter-chip interconnect (ICI) according to a job’s needs, as well as discovering (using breadth first search, who said Leetcode isn’t useful!) and monitoring links (the latter of which becomes a factor in reconfiguration). The data generated by libtpunet also informs scheduling decisions.
Connectivity changes at three points in the lifecycle of a TPU cube: on job start, on failure, and on migration/preemption.
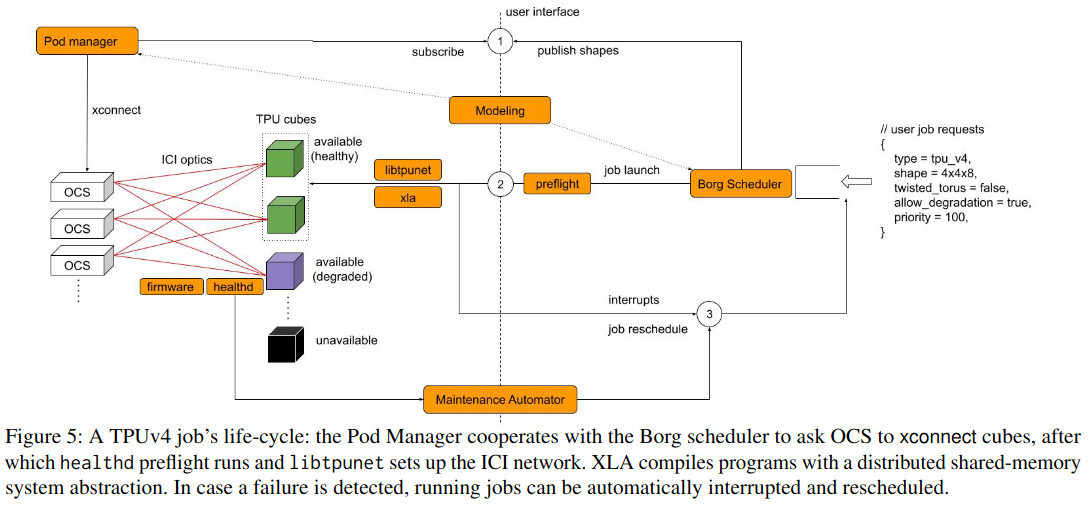
On job start, after a user submits a job that requires multiple cubes, the Borg scheduler selects which cubes to use. Then, the Pod Manager configures the Optical circuit switches (OCSes) to connect these cubes together in the right pattern. If that happens successfully, the Pod Manager communicates this fact back to Borg, which handles deploying the binary that will be executed and running the job.
Second, connectivity changes on failure, as detected by two software components (libtpunet and healthd). For example, when a TPU machine breaks down, an optical circuit switch (OCS) needs maintenance, or a network link starts showing errors. The two aforementioned systems provide signals to Borg/Pod Manager, who update the network topology for running jobs to route around failures. Additionally, these two systems reflect current state in the system’s source of truth, ensuring that future jobs don’t run into the same issues.
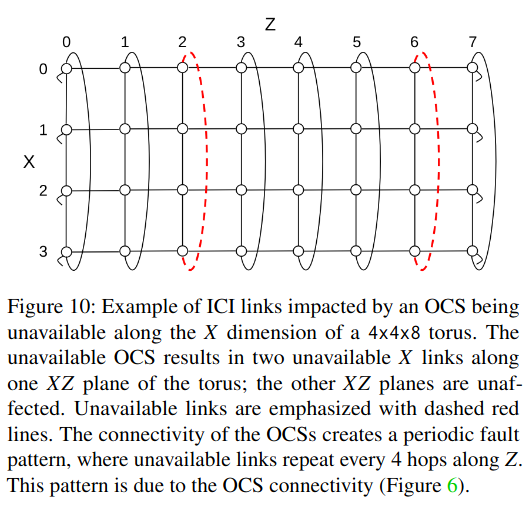
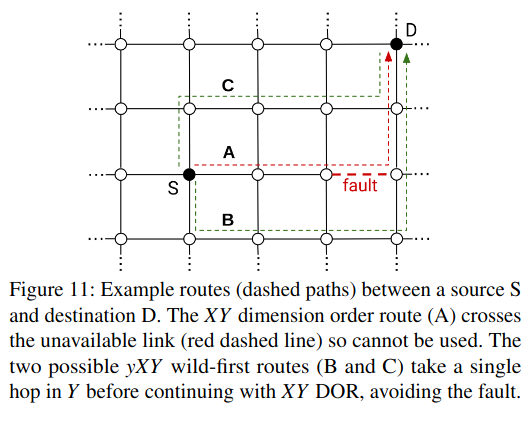
Lastly, connectivity changes on migration/preemption - this can happen when the cluster manager chooses to de-frag a job into fewer cubes, or relocate a job to make room for a larger one. In this case, the system needs to ensure that the new resources and networking links are configured correctly.
How is the research evaluated?
To evaluate the system, the paper includes data on the number of reconfigurations, ability to automate maintenance, and the impact of failure recovery mechanisms on performance.
To evaluate reconfiguration rate, the authors compare the number of xconnect actions with the number of jobs submitted. xconnect handles the low-level changes to networking connections, and varies with the number of jobs.

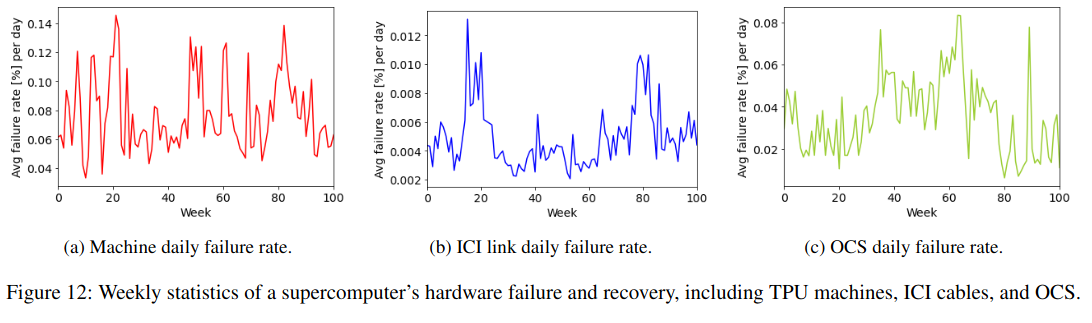
Additionally, the paper contains information on the failure rate of different system components:
In an average supercomputer, each day, 0.08% of the TPU machines, 0.005% of the ICI cables, and 0.04% of the OCS experience a failure. While these values are small, the number of jobs that are impacted by hardware outages is non-trivial because each supercomputer has a large number of machines, ICIs, and OCS. Machine and ICI outages are automatically tolerated by reconfiguring jobs to use spare healthy cubes.
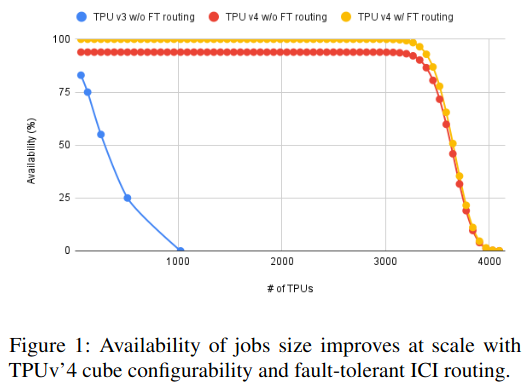
The claim about automatically reconfiguring the system (both in response to failures and to handle changing workloads) is supported by data shared at the beginning of the paper - availability of the system grows, even with significantly larger TPU pods. Interestingly, being able to reconfigure at all has a much higher impact on availability than support for fault tolerant routing.
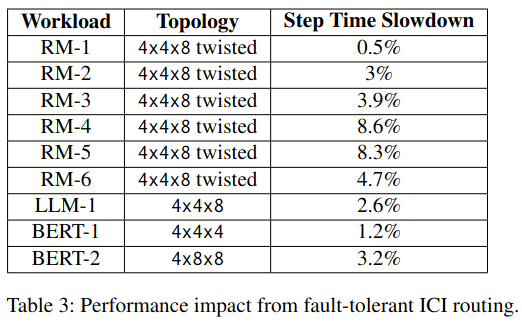
Lastly, the paper notes that there is a non-negligible cost to setting up a job for fault-tolerance, although not all jobs take advantage of the technique.
Specifically, fault-tolerant routing can slow down jobs due to congested network links, most notably for collective operations. This is visible in results for training recommendation models which use “embeddings” to represent data (part of training these models is updating embeddings on other chips, which is performed by collectives), and all-to-all communication to access embeddings on different TPUs.
Conclusion
The infrastructure challenges this paper addresses have become even more critical with the growth in AI model sizes and associated computational demands (although there is active discussion on scaling walls). I’d be interested to know whether the approach and pod-structure should or would scale beyond the current implementation - for example, what happens with even larger TPU pods (or is increasing TPU pod size a non-goal)? Lastly, I found the opportunity to reduce the impact of failures even further through the use of “hot-standbys” without the use of checkpointing (potentially migrating state from a problematic node), and I’m looking to future research on that front.