micahlerner.com
XFaaS: Hyperscale and Low Cost Serverless Functions at Meta
Published January 23, 2024
Found something wrong? Submit a pull request!
Discussion on Hacker News
This is one of several papers I’ll be reading from 2023’s Symposium on Operating Systems Principles (SOSP). If you’d like to receive regular updates as soon as they’re published, check out my newsletter or follow me on the site formerly known as Twitter. Enjoy!
“XFaaS: Hyperscale and Low Cost Serverless Functions at Meta”
Background
Function-as-a-Service systems (a.k.a. FaaS) allow engineers to run code without setting aside servers to a specific function. Instead, users of FaaS systems run their code on generalized infrastructure (like AWS Lambda, Azure Functions, and GCP’s Cloud Functions), and only pay for the time that they use.
Key Takeaways
This paper describes Meta’s internal system for serverless, called XFaaS, which runs “trillions of function calls per day on more than 100,000 servers”.
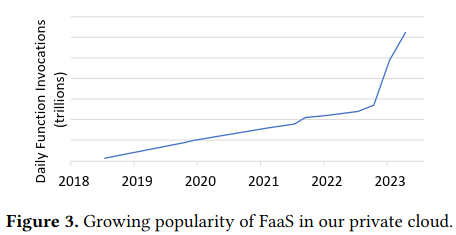
Besides characterization of this unique at-scale serverless system, the paper dives deeper on several challenges that the authors addressed before reaching the current state of the infrastructure:
- Handling load spikes from Meta-internal systems scheduling large numbers of function executions.
- Ensuring fast function startup and execution, which can impact the developer experience and decrease resource utilization.
- Global load balancing across Meta’s distributed private cloud, avoiding datacenter overload.
- Ensuring high-utilization of resources to limit cost increases from running the system.
- Preventing overload of downstream services, as functions often access or update data via RPC requests when performing computation.
How does the system work?
Architecture
The multi-region infrastructure of XFaaS contains five main components: Submitter, load balancers, DurableQ, Scheduler, and Worker Pool.
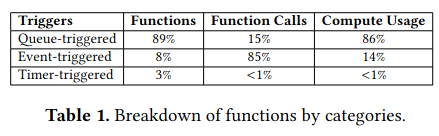
Clients of the system schedule function execution by communicating with the Submitter. Functions can take one of three types:
(1) queue-triggered functions, which are submitted via a queue service; (2) event-triggered functions, which are activated by data-change events in our data warehouse and data-stream systems; and (3) timer-triggered functions, which automatically fire based on a pre-set timing.
The submitter is an interesting design choice because it serves as an entry point to downstream parts of the system. Before the pattern was introduced, clients interfaced with downstream components of the system directly, allowing badly behaved services to overload XFaaS - now, clients receive default quota, and the system throttles those that exceed this quota (although there is a process for negotiating higher quota as needed).
The next stage in the request flow is forwarding the initial function execution request to a load balancer (Queue Load Balancers (QueueLB)) sitting in front of durable storage (called DurableQ) that contains metadata about the function. The QueueLB is one usage of XFaaS’ usage of load balancers, and ensures effective utilization of distributed system resources while preventing overload.
Once the information about a function is stored in a DurableQ, a scheduler will eventually attempt to run it - given that there are many clients of XFaaS, the scheduler, “determine(s) the order of function calls based on their criticality, execution deadline, and capacity quota”. This ordering is represented with in-memory datastructures called the FuncBuffer and the RunQ - “the inputs to the scheduler are multiple FuncBuffers (function buffers), one for each function, and the output is a single ordered RunQ (run queue) of function calls that will be dispatched for execution.”
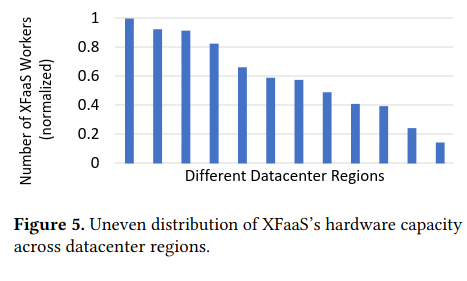
To assist with load-balancing computation, a scheduler can also choose to run functions from a different region if there aren’t enough functions to run in the local-region - this decision is based on a “traffic matrix” that XFaaS computes to represent how much load a region should externally source (e.g. Region A should source functions from Regions B, C, and D because they’re under relatively higher load).
Once the scheduler determines that there is sufficient capacity to run more functions, it assigns the execution to a WorkerPool using a load-balancer approach similar to the QueueLB mentioned earlier.
Given the large numbers of different functions in the system, one challenge with reaching high worker utilization is reducing the memory and CPU resources that workers spend on loading function data and code. XFaaS addresses this constraint by implementing Locality Groups that limit a function’s execution to a subset of the larger pool.
Performance Optimizations
The paper mentions two other optimizations to increase worker utilization: time-shifted computing and cooperative JIT compilation.
Time-shifted computing introduces flexibility to when a function executes - for example, rather than specififying “this function must execute immediately”, XFaaS can delay the computation to a time when other functions aren’t executing, smoothing resource utilization. Importantly, users of the system are incentivized to take advantage of this flexibility as functions have two different quotas, reserved and opportunistic (mapping to more or less rigid timing where opportunistic quota is internally treated as “cheaper”).
Additionally, the code in Meta’s infrastructure takes advantage of profiling-guided optimization, a technique that can dramatically improve performance. XFaaS ensures that these performance optimizations computed on one worker benefit other workers in the fleet by shipping the optimized code across the network.
Preventing Overload
It is critical that accessing downstream services don’t cause or worsen overload - an idea very similar to what was discussed in a previous paper review on Metastable Failures in the Wild. XFaaS implements this by borrowing the idea of backpressure from TCP (specifically Additive increase/multiplicative decrease) and other distributed systems.
How is the research evaluated?
The paper evaluates the system’s ability to achieve high utilization, efficiently execute functions while taking advantage of performance improvements, and prevent overload of downstream services.
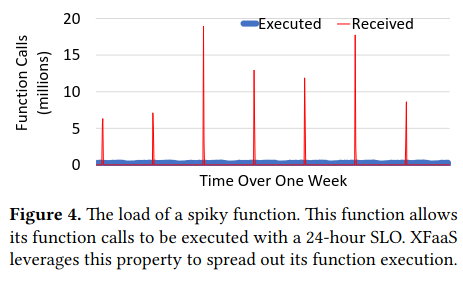
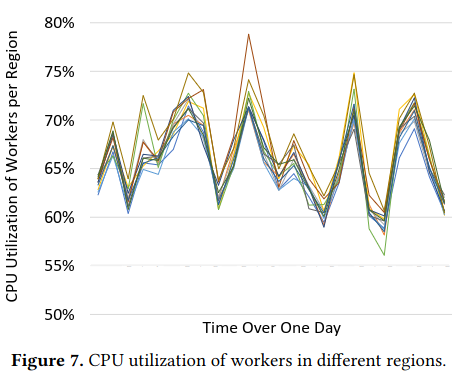
To evaluate XFaaS’s ability to maintain high utilization and smooth load, the authors compare the rate of incoming requests to the load of the system - “the peak-to-trough ratio of CPU utilization is only 1.4x, which is a significant improvement over the peak-to-trough ratio of 4.3x depicted…for the Received curve.”
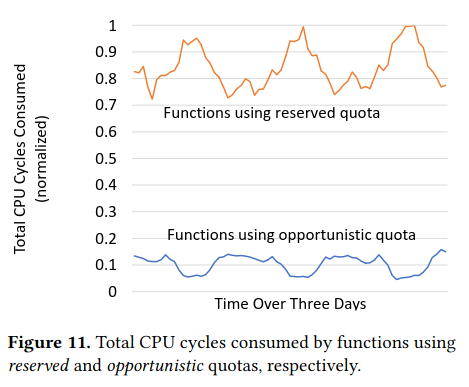
One reason for consistently high load is the incentive to allow flexibility in the execution of their functions, highlighted by usage of the two quota-types described by the paper.
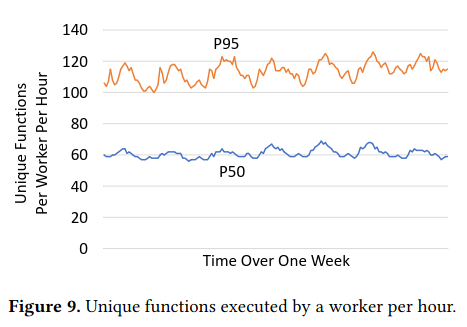
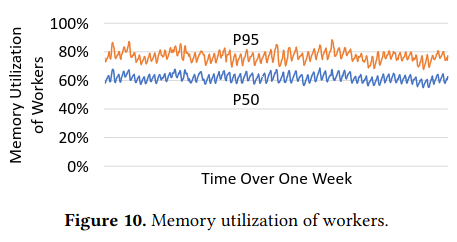
To determine the effectiveness of assigning a subset of functions to a worker using Locality Groups, the authors share time series data on the number of functions executed by workers and memory utiliation across the fleet, finding that both stay relatively constant.
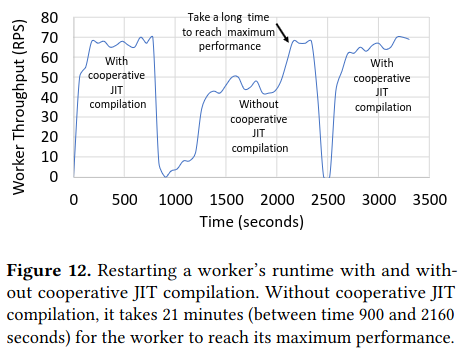
Furthermore, XFaaS’ performance optimizations allow it to maintain a relatively high throughput, visible from contrasting requests per-second with and without profile-guided optimizations in place.
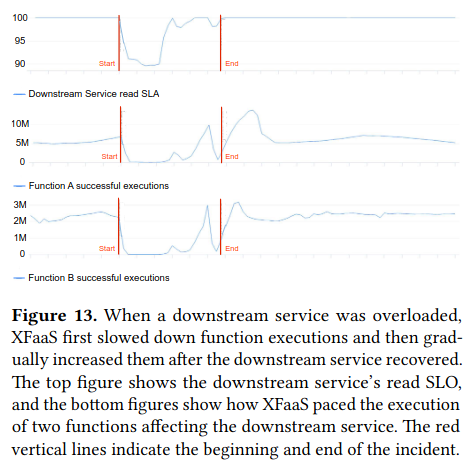
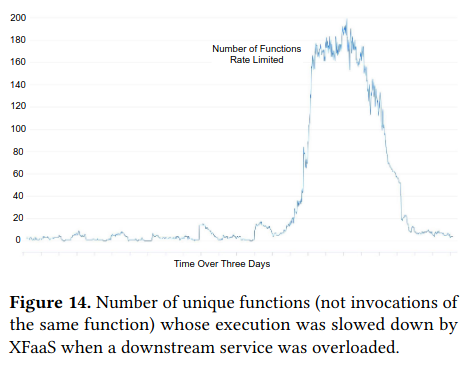
Lastly, the paper presents how XFaaS execution behaves in response to issues with downstream systems (specifically, not exacerabating outages). For example, when there were outage in Meta’s graph database (TAO, the subject of a previous paper review), or infrastructure related to it, XFaaS reduced the execution of functions accessing these services.
Conclusion
The XFaaS paper is unique in characterizing a serverless system running at immmense scale. While previous research has touched on this topic, none have provided specific numbers of utilization, likely omitted due to privacy or business concerns (although Serverless in the Wild comes close).
At the same time, the data on XFaaS comes with caveats, as the system is able to make design choices under a different set of constraints than serverless platforms from public cloud providers. For example, public clouds must guarantee isolation between customers and prioritize security considerations. While XFaaS doesn’t wholly neglect these concerns (e.g. some jobs must run on separate machines and there are some levels of isolation between jobs with these considerations), it otherwise relaxes this constraint. Furthermore, XFaaS explicitly does not handle functions on the path of a user-interaction (even though the paper discusses executing latency-sensitive functions) - this is in contrast with services like Lambda which use Serverless functions to respond to HTTP requests.
While XFaaS is a fascinating system, the paper left me with several questions including whether many of the functions the system executes would actually be better served with a batch job. Furthermore, the authors allude to XFaaS utilization being significantly higher based on “anecdotal knowledge” - while this might be true, it would be useful to know the source of this data to judge whether any differences are in fact meaningful.