micahlerner.com
Elastic Cloud Services: Scaling Snowflake’s Control Plane
Published January 19, 2023
Found something wrong? Submit a pull request!
Elastic Cloud Services: Scaling Snowflake’s Control Plane
What is the research?
Snowflake is a company that makes a globally distributed data warehouseSee Snowflake, Google Cloud or AWS description of data warehouses. . Their product must reliably respond to business-critical customer issued queries, while abstracting away scaling challenges associated with rapidly changing load. Behind the scenes, Snowflake must also reduce single points of failures by deploying across multiple cloud providers and the regions within them - an approach becoming more popular due to projects like Crossplane that simplify “sky computing”
This paper discusses the design and implementation of Elastic Cloud Services (ECS), the critical component of the company’s infrastructure that is responsible for orchestrating workloads. ECS enables the platform to process large amounts of data efficiently and with minimal downtime.
Snowflake previously published workSee The Snowflake Elastic Data Warehouse and Building An Elastic Query Engine on Disaggregated Storage. The latter has a great summary on The Morning Paper. on their underlying infrastructure, but the most recent paper builds on prior research in three main respects. First, it specifically focuses on the component of Snowflake’s data warehouse responsible for coordination across multiple cloud providers. Second, it discusses designing the system with availability in mind, actively making tradeoffs along the way. Lastly, the paper describes novel techniques for autoscaling capacity at scale.
What are the paper’s contributions?
The paper makes two main contributions:
- Design and implementation of Elastic Cloud Services, an at-scale control planeControl planes have come up in previous paper reviews, like Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications. that powers Snowflake
- Evaluation and charactierization of ECS from production deployment
Background
Snowflake infrastructure is divided into three main layers: Elastic Cloud Services (the focus of the paper), a Query Processing layer responsible for executing user queries over a customer’s dataset, and Object Storage (which holds the database records). The full architecture of Snowflake is not the focus of this paper, and is covered in previous researchSee the sidebar in the introduction of this paper review for links to the previous research. .
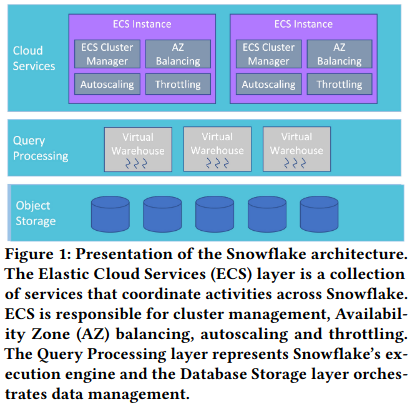
Each Snowflake customer can configure one or more Snowflake warehousesMore information on warehouses here. , providing isolation between different users of the software. When a customer configures a warehouse, it is assigned a versionSnowflake releases new versions on a recurring basis, and publishes info about each release on their developer-facing documentation. of Snowflake software that determines the software a customer’s queries are executed with. Importantly, this configuration doesn’t result in the creation of backing compute resources - instead, Snowflake dynamically scales up when a customer sends queriesThis property of dynamic scaling in response to load is one of Snowflake’s claims to fame. .
How does it work?
Elastic Cloud Services (ECS)
The paper focuses on three main aspects of ECS:
- Automatic Code Management: the code powering the product is upgraded on a continuous basis, and ECS is designed to automatically and reliably handle these upgrades.
- Balancing load across availability zones: ECS coordinates load across multiple cloud providers in order to reduce single points of failure.
- Throttling and autoscaling: the number of requests from customers can increase dramatically and ECS must be able to serve these queries (often achieving this by adding more resources).
The ECS Cluster Manager handles these tasks. When a user requests the creation of a new cluster, the Cluster Manager provisions the necessary resources and creates the cluster in specified cloud providersMore information on the cloud providers that Snowflake supports (and how) is in their docs. . The Cluster Manager also registers the cluster with the control plane, which is responsible for coordinating the activities of the ECS clusters and scheduling user queries on compute resources (represented via warehouses). Once the cluster is registered, it is ready to accept customer queries and perform the necessary processing.
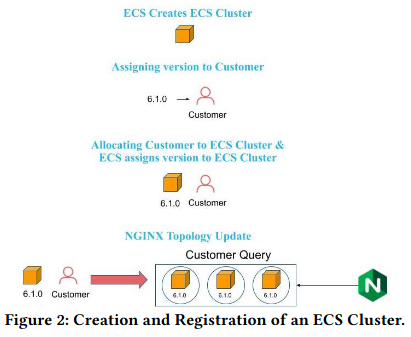
Automatic Code Management
Rollouts
The code that powers Snowflake’s product is constantly receiving updatesThey also document pending behavior changes to the system. . ECS is designed to gradually rollout changes to reduce the likelihood of negative customer impact. This process is fully automated to minimize human error and ensure the fast and reliable rollout of new code. It also includes measures to ensure that customer queries are not interrupted, such as allowing VMs to finish executing their queries before they are shut down.
To rollout updates to a cloud services cluster, ECS first prepares new virtual machines (VMs) with the updated software version. Then, ECS prepares the machines by warming their cachesThe paper doesn’t provide specifics of how the cache is warmed, but I would guess that it could potentially be through a ‘dark rollout’ where currently-executing customer queries are forwarded to the new machines. , and starts directing user queries to the new VMs.
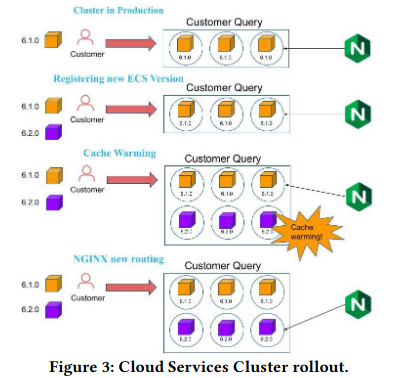
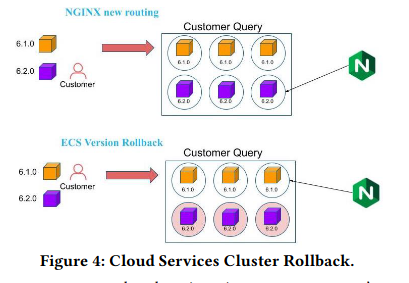
To minimize disruption to ongoing queries, VMs using the previous version continue to operate until their workload is finished. Running VMs with new and old versions of the software simultaneously is more expensive resource-wise, but allows fast rollbacks in the event of customer impactThis is amazing from a reliability perspective, and is also discussed in the SRE book. . Additionally, customers can pin to a specific version of Snowflake’s code if they experience regressions in the new version.
Pools
At scale, machines fail or perform suboptimally for a wide variety of reasonsThis effect is often called fail-slow at scale, and is discussed in more detail in papers like Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems. To combat this, ECS actively manages the cloud resources underlying its computing nodes, keeping track of the healthThe paper mentions using health metrics like, “memory management, CPU, concurrency characteristics, JVM failures, hardware failures”. of individual nodes (and deciding when to stop using unhealthy ones).
Based on this monitoring, ECS moves VMs between cluster pools, each containing resources matching one of five distinct stages in a VM’s lifecycle:
- Free Pool: contains VMs that are ready to be used.
- Quarantine Pool: contains VMs that need to be removed from their clusters to resolve any pending tasks
- Active Pool: contains healthy VMs that are part of a cluster and actively handling customer workloads.
- Graveyard Pool: includes VMs prepared for termination.
- Holding Pool: for debugging purposes, Snowflake developers and automated systems can remove VMs from active service, but refrain from shutting down the underlying resources.
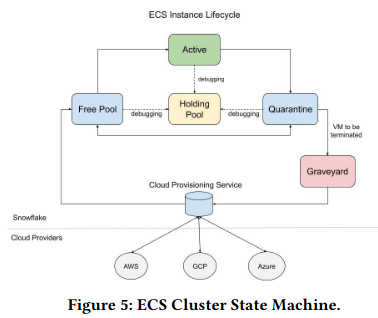
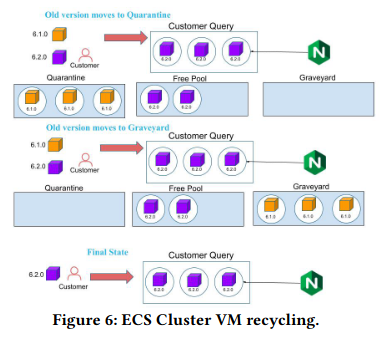
The paper discusses two concrete usages of the pools. The first is a set of state transitions that occur when the cluster is upgraded, as the VMs running the old version of the software move from active to quarantine, and then finally to graveyard.
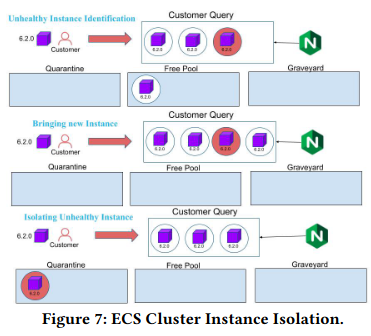
The second example covers an example where a machine shifts from the Free Pool to the Quarantine Pool when it becomes an outlier with respect to processing customer queries.
Balancing Across Availability Zones
ECS (Elastic Cloud Service) loadbalances across availability zones in order to ensure minimal customer impact in the event of failure within cloud provider regionsCloud provider failures are discussed at length in a previous paper review, Metastable Failures in the Wild . By distributing VMs (virtual machines) evenly across different availability zones, ECS can redirect requests to VMs in a different zone if one zone experiences an outage or becomes unavailable for some other reason. This approach helps to ensure that the service remains available and responsive to customers, even in the face of unexpected disruptions. Loadbalancing across availability zones is a common practice in cloud computing, as it helps to improve the resilience and reliability of service.
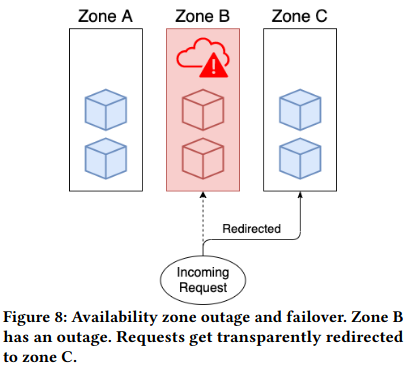
The paper describes how ECS implements two types of loadbalancing: cluster-level balancing (which aims to distribute the VMs for a customer’s cluster across multiple zones) and global-level balancing (which aims to distribute total VMs evenly across zones).
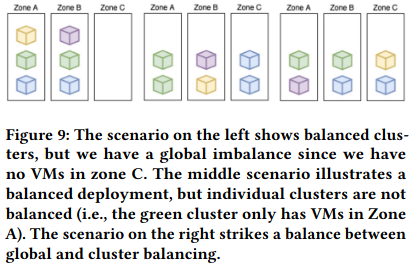
The paper provides high-level details on how the loadbalancing works:
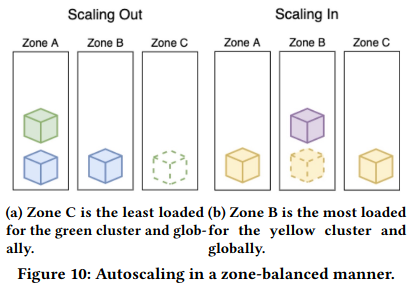
When scaling a cluster out, ECS picks the least loaded zone globally out of the set of least loaded zones for that cluster. Similarly, when scaling a cluster in, ECS picks the most loaded zone globally out of the set of most loaded zones for that cluster.
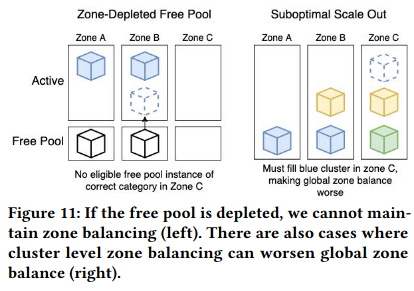
There are times when scaling via these two strategies doesn’t work or when they conflict with each other. For example, if there are no VMs to assign to a cluster in a given zone, it might not be possible to execute cluster-level balancing. Another situation where the balancing can be suboptimal is when “correctly” balancing a cluster across zones results in a global imbalance containing many clusters with VMs in a single zone.
Throttling and Autoscaling
The load that customers send to Snowflake varies over time. ECS uses two main approaches to handle the unpredictably of user traffic:
- Throttling: the execution of customer queries should be isolatedIf the queries are not isolated well, one would see the Noisy Neighbor problem. and should not consume excessive resources.
- Autoscaling: the load that customers send to Snowflake’s database varies over time, and the underlying infrastructure needs to automatically scale (also known as performing autoscaling) in response.
When designing ECS’s solutions to these problems, the authors balanced five factors:
- Responsiveness: queries should start running without user-visible delay
- Cost-efficiency: Snowflake shouldn’t retain unnecessary resourcesSnowflake’s cost model also allows customers to optimize their spend - see this discussion from their official blog and posts from external developers. .
- Cluster volatility: Minimize unnecessary changes to cluster configurations, as frequent changes impact performance and cost.
- Throughput: the system should scale to meet demand.
- Latency: queries should complete in a timely manner (and not be impacted by issues like skewIn particular, this is a often a problem with joins. See an example discussion here. )
To implement throttling, Snowflake uses an approach called Dynamic Throttling that makes scaling decisions based on VM usage for customer queries. Instead of using static concurrency limits that do not take into account the specific demands of each workload, dynamic throttling calculates limits based on CPU and memory usageMemory pressure is also a problem in other systems, like Elastic Search. of the VMs. When a VM is executing a query and hits these limits, it doesn’t accept new queries until health metrics return to normal. This approach helps to prevent the system from becoming overwhelmed by requests and ensures a consistent service experience for customersThe paper also mentions that different accounts and users with an account are isolated from one another in order to stop a single entity from causing noisy-neighbor behavior. .
Autoscaling uses load signals similar to those that Dynamic Throttling relies on. The algorithm for autoscaling a cluster also takes into account factors like churn of VMs, and aims to minimize scaling up and scaling down. It is capable of scaling both horizontally (adding more VMs) and vertically (increasing their size).
How is the research evaluated?
The evaluate the system, the paper considers the performance of ECS’s zone balancing, autoscaling, and throttling.
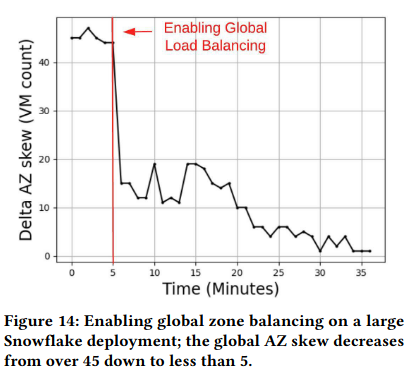
To evaluate load balancing, the authors include information on how ECS reduced skew, a measure of “the difference between the number of VMs in the most loaded zone and the least loaded zone”. ECS’s load balancing reduced average global skew (VM differences from across a deployment) from 45 to 5 and almost eliminated skew within a cluster. By limiting skew, Snowflake deployments are less exposed to an outage in any one cloud region. Furthermore, balanced deployments simplify scaling as there are fewer VM-constrained Free Pools.
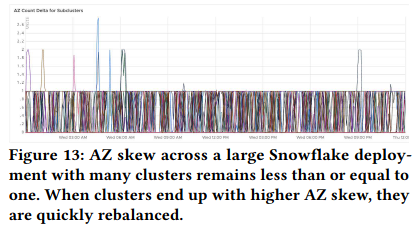
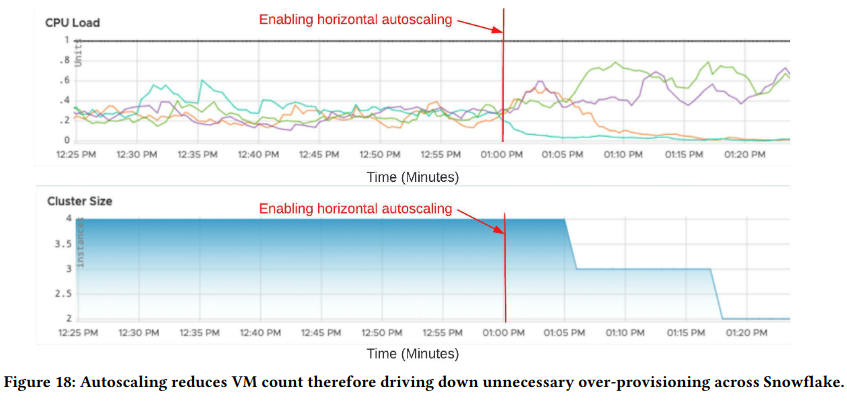
To evaluate throttling and autoscaling, the paper includes several examples from production. One example usage of autoscaling is in response to noisy neighbor problems - after detecting the issue, ECS automatically mitigated by adding VMs to the impacted cluster. ECS also automatically scales down to reduce cost.
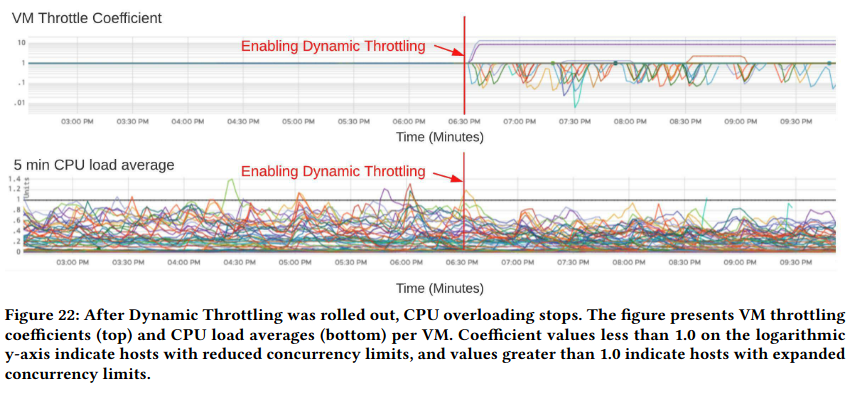
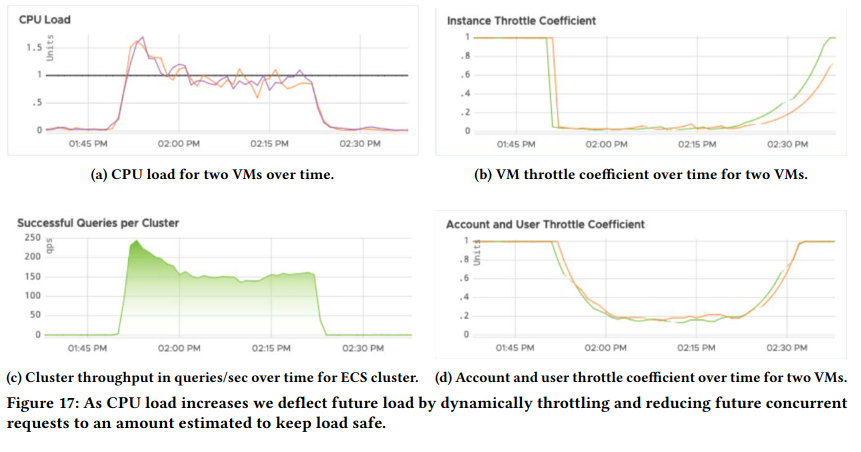
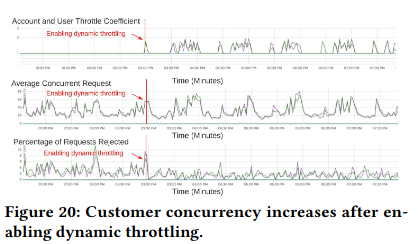
Dynamic throttling is similarly beneficial. When a cluster was experiencing high load, ECS throttled requests to the impacted VMs, forwarding queries to VMs capable of servicing them. This smooths customer load by directing user queries to machines that are actually capable of processing them.
Conclusion
The paper on Snowflake’s Elastic Cloud Services provides an overview of the control plane responsible for running the company’s database product. I’m hopeful that several of the interesting topics the authors touch on are the subject of future publications, as the research is unique in several respects. First, its focus is unlike many papers covering distributed databases - prior art often centers on database internals or underlying consensus algorithms. The paper is also novel in that it discusses an at-scale approach to running across multiple cloud providers, a solution that is becoming more prevalent in the era of “sky computing”. While Snowflake’s implementation of cross-cloud deployment is custom to their system, the growth of products like Crossplane may generalize this design, making the path easier for future implementers.