micahlerner.com
Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints
Published January 30, 2024
Found something wrong? Submit a pull request!
This is one of several papers I’ll be reading from 2023’s Symposium on Operating Systems Principles (SOSP). If you’d like to receive regular updates as soon as they’re published, check out my newsletter or follow me on the site formerly known as Twitter. Enjoy!
Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints
What is the research and why does it matter?
Training AI models requires a large amount of compute resources, in particular GPUs. Many large companies purchase their own GPUs, leading to both up front costs of acquisition, as well as ongoing spend to power the clusters where the GPUs are hosted. Furthermore, at an organization with many projects requiring these resources, there is contention for compute time.
While the first two sources of cost are difficult to minimize, effective usage of compute time is a growing area of research. One way that teams are making gains is by improving the reliability of model training - if a machine involved in training fails, in-progress work may be lost. Motivated by data that existing solutions don’t handle this case well, the authors propose a framework for limiting the amount of wasted resources - “According to the report from OPT-175B training…about 178,000 GPU hours were wasted due to various training failures.”
The Gemini paper aims to solves this problem by providing a failure recovery system for training runs. Rather than solely relying on far remote storage which is costly to read/write to, Gemini builds a multi-level cache comprising GPU memory, local and remote CPU memory, with persistent storage as a last resort. This new design and implementation is able to successfully achieve 13x faster failure recovery without significantly impacting training.
Motivation
A key idea in Gemini is “checkpointing” progress so that when a failure happens, the system doesn’t need to recompute results.
The paper lays out three factors to “wasted time” in existing checkpoint-based systems:
- Checkpoint time: how long a model takes to build an intermediate checkpoint.
- Checkpoint frequency: how often a training system builds intermediate states.
- Retrieval time: how long it takes to fetch a checkpoint.
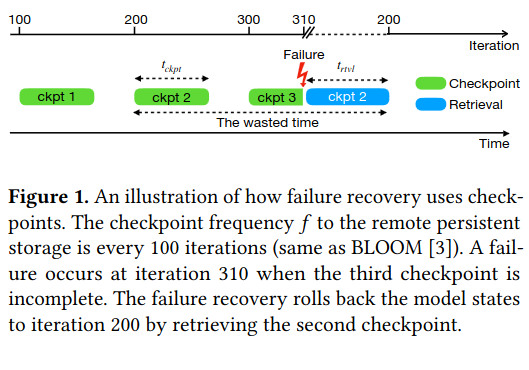
These factors manifest in existing systems where checkpoints are resource-intensive to create, limiting how often the system produces them. In turn, this impacts the freshness of checkpoints and increases “wasted time” - a system resuming from an old checkpoint will redo more computation.
Beyond creating the checkpoints, the system must store them and make them available with low-latency - to drive down wasted time, Gemini proposes a system that aims to “maximize the probability of failure recovery from checkpoints stored in CPU memory”.
How does the system work?
There are two parts of the Gemini system: the checkpoint creation module and the failure recovery module.
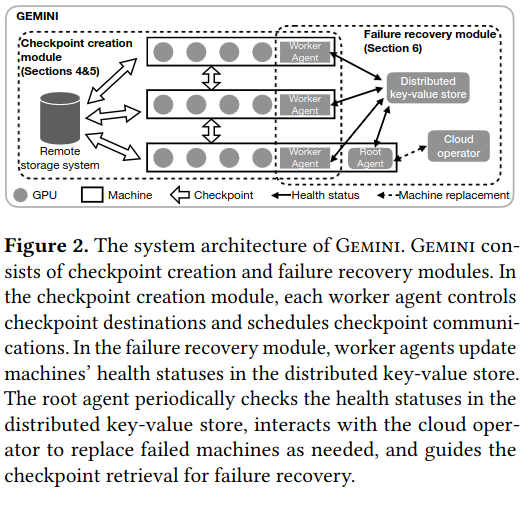
The checkpoint creation module creates checkpoints and figures out where to store them. It implements a distributed multi-level distributed cache of checkpoints stored in CPU Memory, GPU Memory, and Remote Storage.
The failure recovery module is responsible for evaluating whether a component of the system has failed and needs replacement - it contains contains four components:
- Gemini worker agents: each node participating in training has a process that reports on machine health and provides state updates.
- Root agent: worker agent promoted to leader via distributed consensus algorithm (e.g. Raft) and provides commands to workers (e.g. recover from failure).
- Distributed KV Store: stores state on the machines in the network and assists in electing new root agents on failure.
- Cloud Operator: the root agent communicates with a hosting provider (e.g. a central schedular) to perform actions like requesting more resources (e.g. more machines with GPUs).
Technical Challenges
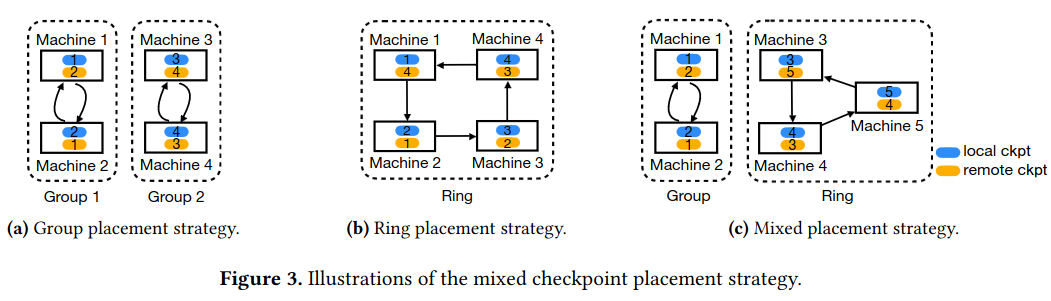
The system aims to minimize “wasted time” by limiting the impact of machine failure. Key to the system’s approach is distributing checkpoints across machines in the network - the paper investigates different configurations of where to place the checkpoints - it calls them group, ring, and _mixed. The paper also includes pseudocode of the group algorithm.

Distributing checkpoints is not without its cost, particuarly to networking resources - as model training also uses the network, competing traffic could impact performance. To address this the authors implement traffic interleaving, which attempts to send the checkpoints over the network in a way that doesn’t interfere with other network traffic associated with training.
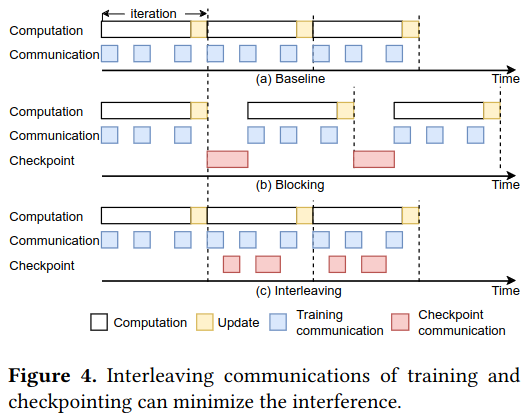
After creating a checkpoint, Gemini transfers it to remote GPU memory on another machine in the network, then that machine transfers it to CPU memory (which is relatively cheaper and more abundant).
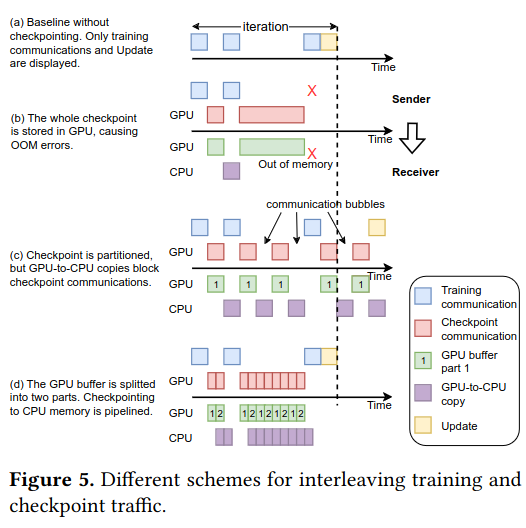
A simple implementation following this approach transfer the whole checkpoint at once across the network to remote GPU memory. As checkpoints can be quite large, this implementation requires the destination machine to set aside a large amount of GPU memory just for receiving checkpoints (or risk hitting out of memory errors). Instead, the paper proposes splitting up a checkpoint into partitions, then incrementally transferring them over the network.
The authors also describe an approach to online profiling where the dynamics of network traffic are learned over time and then eventually feed into the decision making for sending traffic over the network. By combining this idea with checkpoint partitioning, Gemini is able to make decisions about when to send buffers over the network.

Resuming from failure
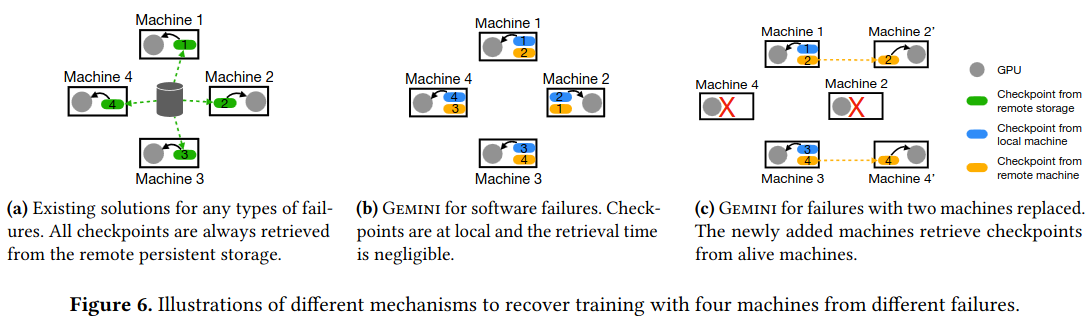
The authors describe two different failure types: software failure (e.g. the code running training has a bug) and hardware failure (e.g. the machine loses network connectivity or a hard drive breaks). Critically, GEMINI treats the two types differently because of the impact they have on the in-memory data used to restore from checkpoint - a software failure can likely recover from checkpoint stored in memory, while a hardware failures often requires a combination of machine replacement and fetching checkpoints from a different computer in the network.
How is the research evaluated?
The research evaluates GEMINI’s impact on training efficiency, and effectiveness in traffic interleaving. Additionally, the authors make projections around the system’s scalability and impact it could have in training large language models.
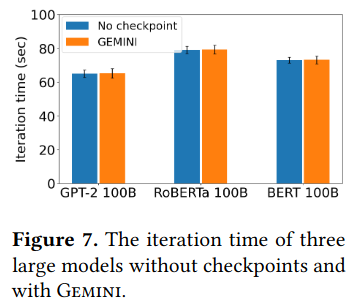
For training efficiency, the paper measures whether GEMINI changes training time, wasted time, and checkpoint time. When training three large models, the paper finds that GEMINI doesn’t increase iteration time (time where the model is doing work before it must pause to communicate) while significantly reducing wasted time in the presence of machine failures. Checkpoint time also goes down when compared to existing checkpoint-based training solutions.
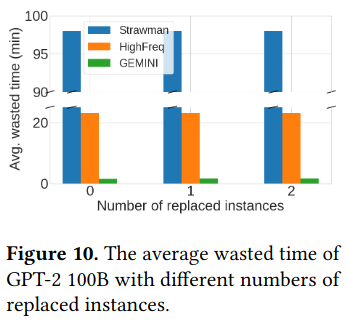
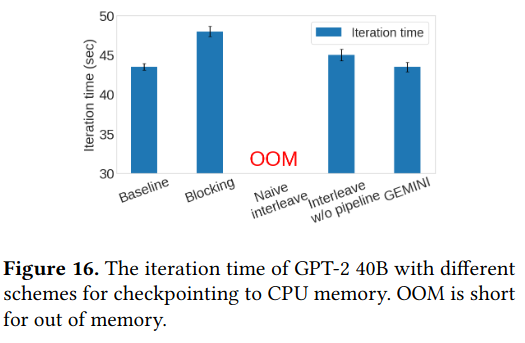
The paper also measures the effectiveness of traffic interleaving (specifically by tracking iteration time), comparing the Gemini approach against existing baselines and other approaches (e.g. the naive implementation without checkpoint partitioning) - the Gemini solution doesn’t result in out of memory issues while keeping the iteration time the same and being able to recover from failure.
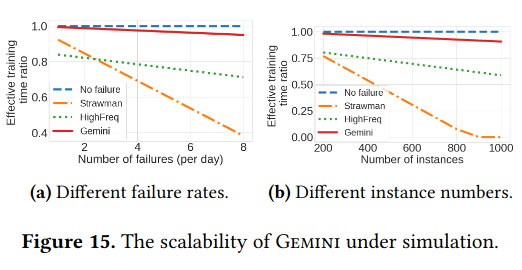
Lastly, the research contains projections about Gemini’s ability to reduce wasted time if the system was applied to training a large language model - while the results of this projection seem promising, it seems like there is more work to gather the effectiveness of Gemini at scale.
Conclusion
Gemini is a system that could potentially dramatically reduce wasted time in training AI models - as models continue to grow and use more resources in a distributed setting, recovering from failure will become even more of a concern than it already is.
One of my main takeaways from the Gemini paper is around the application of systems ideas to AI models and their training. For example, Gemini takes advantage of common patterns like reliance on a distributed key-value store, leader election, and a multi-tier memory system. The idea that adopting well-known patterns could lead to dramatic performance and reliability improvements in this new type of serving system is quite exciting - it means there is a lot of low hanging fruit!
I’m looking forward to further developments in this space, and hope to see a followup paper from the authors soon with more data on training a model at scale (or alternatively a reference to using Gemini-like techniques from other organizations).